6. Deep Learning
Micheal Nielson, Jan 2014
A brief introduction about Convolutional Neural Networks(CNN), Recurrent Neural Nets(RNN) and the recent progress of deep nets in real time applications like speech recognition, image recognition and many others are given below.
Convolutional Networks:
Networks with fully connected layers though obtains accuracy of about 98% it does not account the spatial structure of the images. The input pixels which are close and far apart are treated in the same footing.
CNN are fast are fast to train and well adapted to classify images. It uses three ideas : local receptive fields, shared weights and pooling. The region in the input image is known as local receptive field when a small region of input neurons are connected to a single hidden neuron. Each connection learns a weight and the hidden neurons learn the overall bias.
Convolutional Networks:
Networks with fully connected layers though obtains accuracy of about 98% it does not account the spatial structure of the images. The input pixels which are close and far apart are treated in the same footing.
CNN are fast are fast to train and well adapted to classify images. It uses three ideas : local receptive fields, shared weights and pooling. The region in the input image is known as local receptive field when a small region of input neurons are connected to a single hidden neuron. Each connection learns a weight and the hidden neurons learn the overall bias.
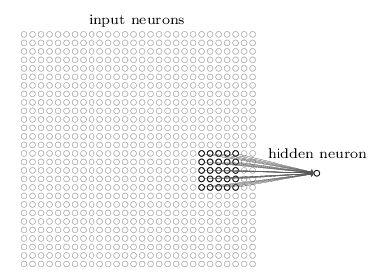
Local receptive field
CNN are adapted to translational invariance. Which means it doesn't matter where the object is, but as long as the object is in the image networks say that there is an object regardless of its position. The map from the input layer to hidden layer is called feature map. The weights and bias defining the feature map is the shared weight and bias. This shared weights and bias is called kernel or filter.
CNN contain pooling layers. It also known as sub-sampling or max-pooling layer. These layers simplify the information in the output from the convolution layer. Another approach called L2 pooling can also be used, it takes square root of the sum of the squares of the activations in the region.
Input layer ----> convolutional layer ------> pooling layer ---->MLP
The results can be improved by adapting to few ideas: Rectified Linear units(ReLu) based networks outperformed than sigmoid activation based networks. Also, expanding the training data improves the results with good accuracy.
Thus by using CNN reduces the number of parameters by making the learning problem easy.
Recurrent Neural Networks (RNN):
The time varying behavior of a neural network is known as recurrent neural network. Where the activations in the hidden and output neurons is determined by the current and earlier inputs. Because of unstable gradient problem, training with RNN is very difficult. The gradient becomes smaller and smaller as it is propagated back through time which makes the learning extremely slow. If the network runs for a long time it makes the gradient extremely unstable and hard to learn. This problem is solved by using Long Short Term Memory Units(LSTM).
Future of Neural Networks:
# Intention-driven user interfaces: Example -Apple siri, wolfram Alpha, IBM's Watson.
CNN contain pooling layers. It also known as sub-sampling or max-pooling layer. These layers simplify the information in the output from the convolution layer. Another approach called L2 pooling can also be used, it takes square root of the sum of the squares of the activations in the region.
Input layer ----> convolutional layer ------> pooling layer ---->MLP
The results can be improved by adapting to few ideas: Rectified Linear units(ReLu) based networks outperformed than sigmoid activation based networks. Also, expanding the training data improves the results with good accuracy.
Thus by using CNN reduces the number of parameters by making the learning problem easy.
Recurrent Neural Networks (RNN):
The time varying behavior of a neural network is known as recurrent neural network. Where the activations in the hidden and output neurons is determined by the current and earlier inputs. Because of unstable gradient problem, training with RNN is very difficult. The gradient becomes smaller and smaller as it is propagated back through time which makes the learning extremely slow. If the network runs for a long time it makes the gradient extremely unstable and hard to learn. This problem is solved by using Long Short Term Memory Units(LSTM).
Future of Neural Networks:
# Intention-driven user interfaces: Example -Apple siri, wolfram Alpha, IBM's Watson.
 RSS Feed
RSS Feed
