5. Why are deep neural networks hard to train?
Micheal Nielson, Jan 2015
Compared to shallow networks , deep networks are much more powerful and solve complex problems with good approximation. But deep networks doesn't perform so well compared to shallow networks because of vanishing gradient problem. Which means the different layers in the deep network learn at different speeds. Early layers learn slow compared to the later layers.
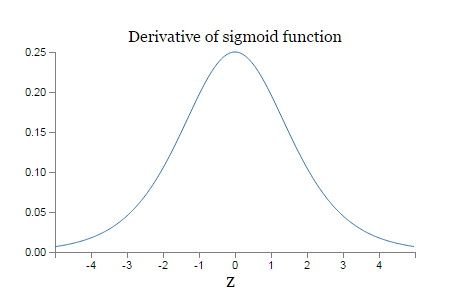
The vanishing gradient problem is well understood from the sigmoid function. The derivative reaches maximum at 1/4. The weights are initialized using gaussian with 0 mean and SD 1. The weights ll be < 1/4. By taking the product the gradient ll tend to decrease exponentially. As the number of terms increases the product ll be smaller and smaller. If the weights are large ,which means greater than 1 , then another problem occurs called exploding gradient problem.
The vanishing gradient problem can be solved by using ReLu activation function in place of sigmoid activation. It can also be solved by initializing the network using unsupervised training.
The vanishing gradient problem can be solved by using ReLu activation function in place of sigmoid activation. It can also be solved by initializing the network using unsupervised training.
 RSS Feed
RSS Feed
